개요
이번 글에서는 활성화 함수의 종류에 대해 이야기하겠다.
활성화 함수의 역할은 선을 비선형으로 만드는 것으로 목적이다.
종류
 |
|
| Sigmoid | tanh |
|
|
| ReLU | LeakyReLU |
이전 예시로 사용한 Sigmoid의 특징부터 이야기하자
어떤 입력값이든 0~1사이의 값으로 결과를 압축해 주는 역할을 한다. 이중분류에서는 마지막 아웃풋에서도 사용한다.
뉴런의 firing rate를 잘표현하다는데 그건 무슨 의미인지 모르겠다.
Activation Function Thinking Point
Sigmoid는 현재 잘 안쓰인다. 왜 그럴까? 다음과 같은 문제점들이 있다.
기울기 죽이기(Killing gradients)
역전파(BackPropagation) 진행 시 중요한 건 미분의 값이다. Sigmoid의 입력값이 엄청 크거나 작은 값의 미분값은 0에 근접해진다. Chain Rule 적용 시 곱해지는 값이 0이 되어 진행하며 사랴져 버릴 것이다.
(물론 BCE Loss에서는 Sigmoid의 역전파는 시그마-Y로 전달되어 괜찮다.)
기억할 것은 역전파가 진행되며 기울기값이 사라지면 안된다.
Not Zero-Centored(오해)
평균이 0이 아니어 생기는 문제가 있다.
Zero-Centored가 아니면 생기는 문제는 조건이 필요하다. 모든 입력값이 같은 부호여야 한다.
문제점으로 가중치 업데이트 시 모두 같은 부호로 진행되어 발생한다고 한다.
예로 w1은 음의 방향 w2는 양의 방향으로 업데이트가 되어야 하는데
w1은 양의 작은 것 w2는 양의 방향 이런 식으로 되어서 느리게 학습이 된다는 것이다.
진짜로 그런지 알아보자(중요하지는 않음 양이 많음).
2종류의 Loss Function과 3종류의 Activation Function으로 가중치가 업데이트 시 진행되는 식을 작성하겠다.
Y(target),L(lossfunction),H(activationfunction)y(output)
Loss Function
L1=−Yln(H)−(1−Y)ln(1−H),L2=(Y−H)2
Activation Function
H1=Max(y,0),H2=111+e−y,H3=tanh(y)
output
y=wx+b
Chain Rule
∂L∂w=∂L∂H∂H∂y∂y∂w
∂L1∂H=−YH+1−Y1−H,∂L2∂H=−2H
∂H1∂y=x<−bw:0,x≥−bw:1∂H2∂y=H(1−H)∂H3∂y=(1−H)(1+H)
∂y∂w=x
앞서 입력값이 같은 부호일 때 발생하는 문제이므로 두 가지 입력을 상정해 보겠다.
∂L∂w1,∂L∂w2
각 입력값에 따라 편미분 값의 곱이 음수라면 서로 반대방향으로 간다는 것이다.
그림을 한번 보자.

∂L1∂H1∂H1∂y∂y∂w1=(−YH1+1−Y1−H1)(w1x1+w2x2+b<0:0,w1x1+w2x2+b≥0:1)x1
∂L1∂H1∂H1∂y∂y∂w2=(−YH1+1−Y1−H1)(w1x1+w2x2+b<0:0,w1x1+w2x2+b≥0:1)x2
((−YH1+1−Y1−H1)(w1x1+w2x2+b<0:0,w1x1+w2x2+b≥0:1))2x1x2
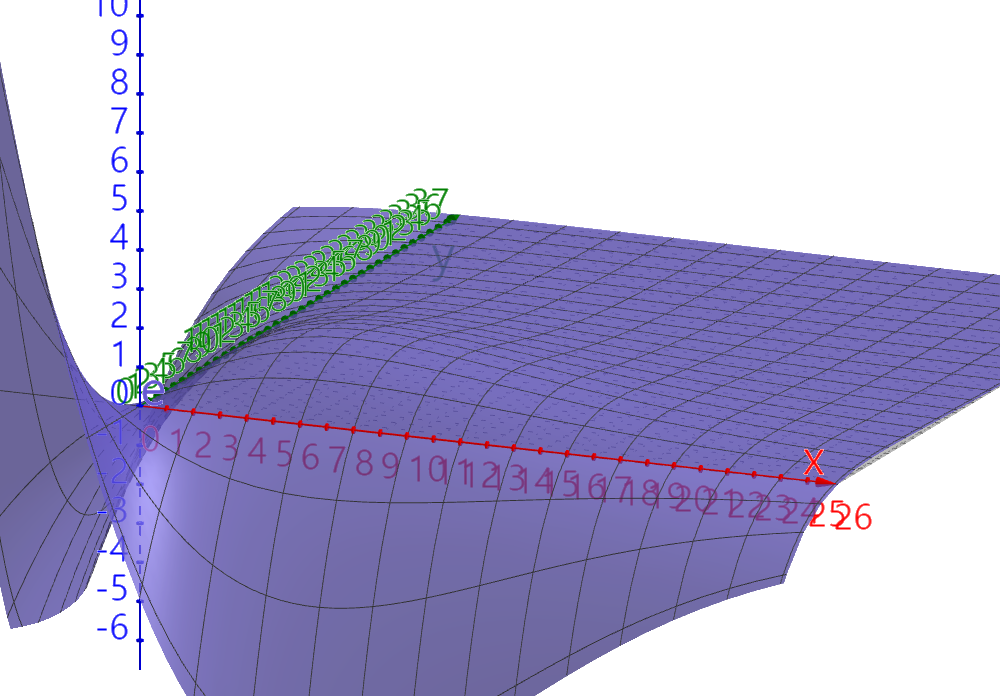
∂L1∂H2∂H2∂y∂y∂w1=(−(1−H2)Y+(1−Y)H2)x=(H2−Y)x1
∂L1∂H2∂H2∂y∂y∂w2=(−(1−H2)Y+(1−Y)H2)x=(H2−Y)x2
(H2−Y)2x1x2
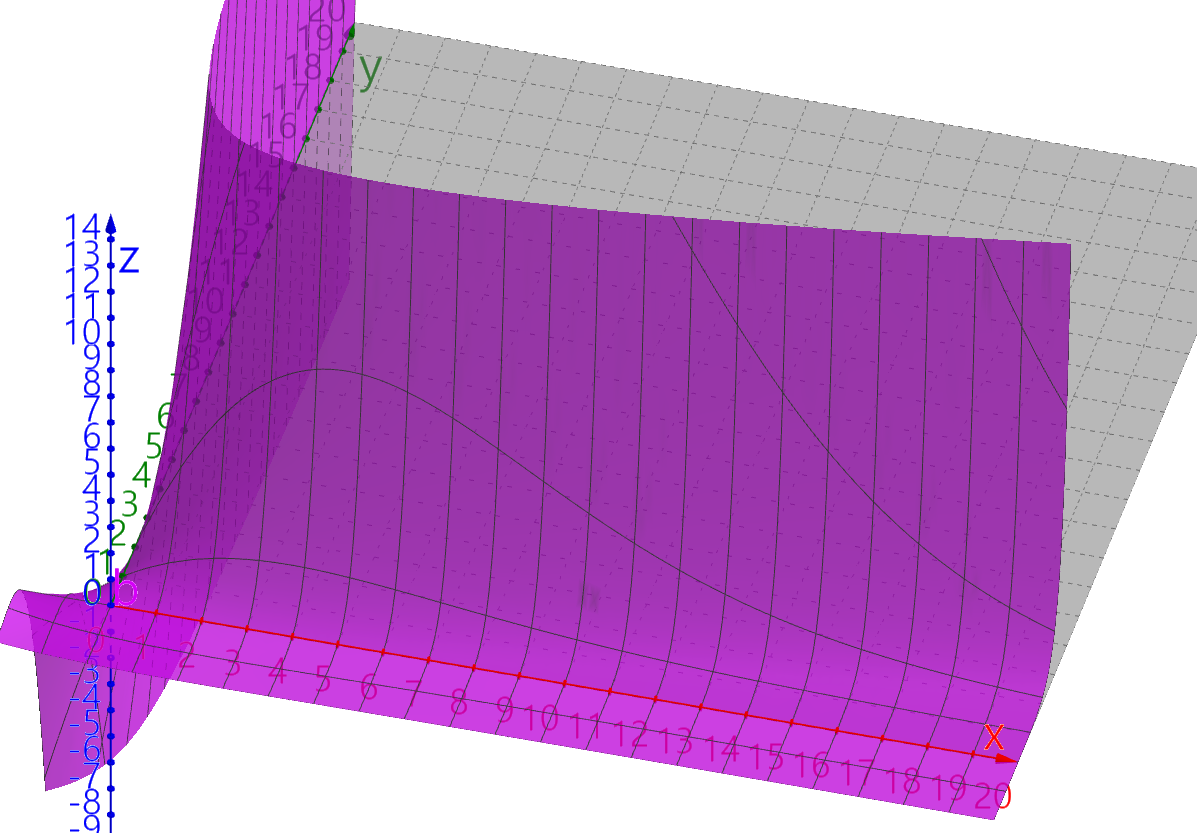
∂L1∂H3∂H3∂y∂y∂w1=(−YH3+1−Y1−H3)(1−H23)x1
∂L1∂H3∂H3∂y∂y∂w2=(−YH3+1−Y1−H3)(1−H23)x2
((−YH3+1−Y1−H3)(1−H23))2x1x2
tanh일때도 편미분 곱은 입력값이 모두 양수라면 양수이다.
여기서 알 수 있듯 저게 문제인가 싶다. 어떠한 Activation이 오든 다 같은 문제가 발생하는 것 같다.
L2일 때도 같은 지만 보자.
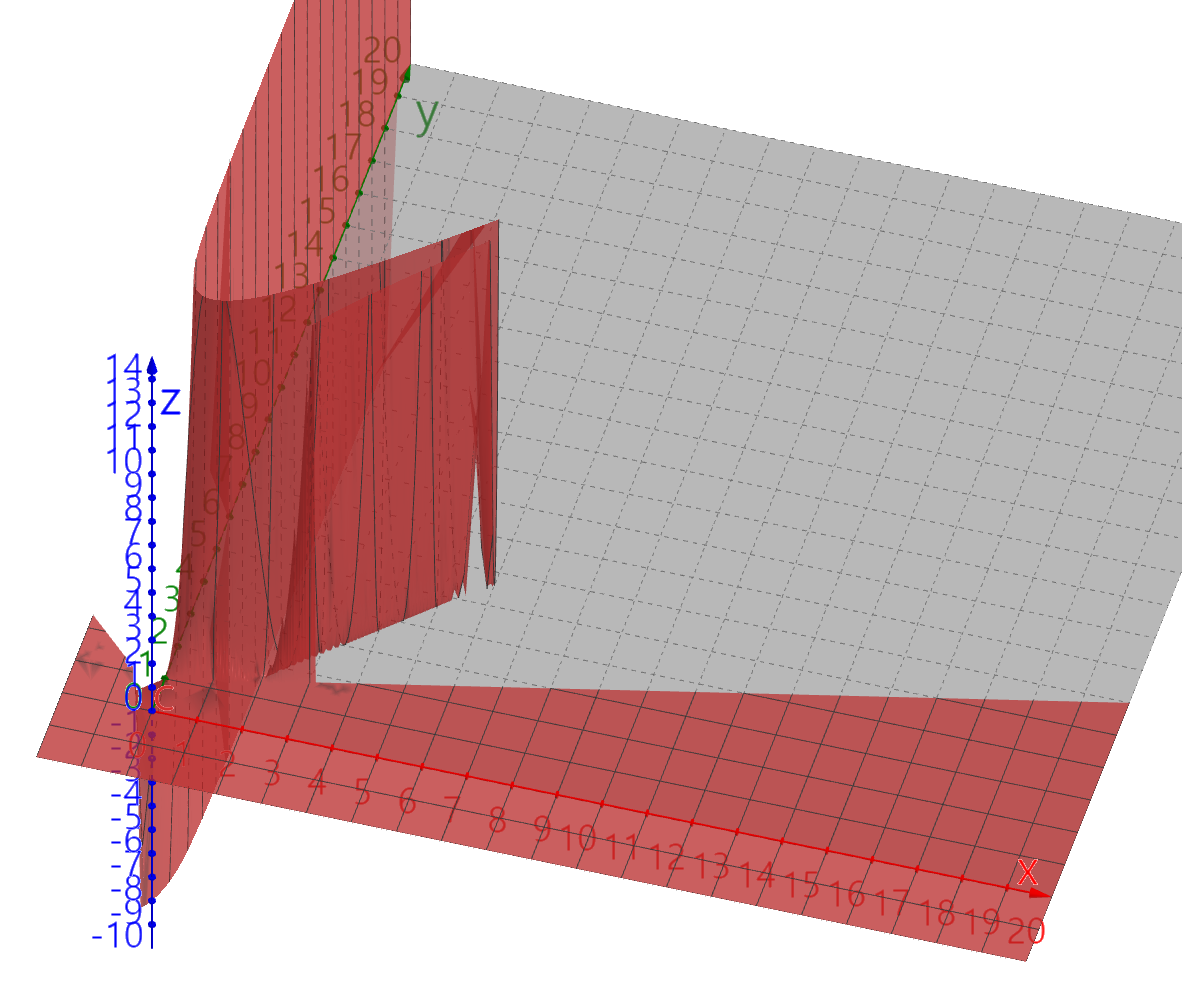
∂L2∂H1∂H1∂y∂y∂w1=−2H1(w1x1+w2x2+b<0:0,w1x1+w2x2+b≥0:1)x1
∂L2∂H1∂H1∂y∂y∂w2=−2H1(w1x1+w2x2+b<0:0,w1x1+w2x2+b≥0:1)x2
(2H1(w1x1+w2x2+b<0:0,w1x1+w2x2+b≥0:1))2x1x2

∂L2∂H2∂H2∂y∂y∂w1=−2H22(1−H2)x1
∂L2∂H2∂H2∂y∂y∂w2=−2H22(1−H2)x2
(−2H22(1−H2))2x1x2

∂L2∂H3∂H3∂y∂y∂w1=−2H3(1−H3)(1+H3)x1
∂L2∂H3∂H3∂y∂y∂w2=−2H3(1−H3)(1+H3)x2
(−2H3(1−H3)(1+H3))2x1x2
L2역시 Activation과 Loss 함수와 별개로 입력이 같은 부호라면 zero-centored 문제와 별개로 똑같이 발생한다.
흔히 cs231n에서 언급된 zero-centored의 zigzag 표현은 거기서 제안한 상황이라면 모든 곳에서 발생하는 것으로 보인다.
이 문제에 대해 의견 주시면 감사드린다.
zero-centored문제는 이해가 되지 않고 결정적으로 sigmoid가 안 쓰이게 된 이유도 아니다.
비용문제
더 이유가 있을 수 있겠지만 비용문제가 존재한다.
ReLU vs. Sigmoid Function in Deep Neural Networks
ReLU vs. Sigmoid Function in Deep Neural Networks: Why ReLU is so Prevalent? What's all the fuss about using ReLU anyway?. Made by Ayush Thakur using W&B
wandb.ai
위 기사를 보면 학습속도 및 성능에서 relu의 우월적으로 높다.
relu는 max함수로 이의 계산량은 if문과 같으며 지수함수를 사용하는 sigmoid에 비해 현저히 빠르다.
ReLU
흔히 쓰이는 Activation Function으로 max(0,wx+b)로 간단한 계산이 장점이 있다.
relu의 단점은 bottleneck을 넘지 않는 상황이면 학습이 아예 진행이 안 되는 것이다.
tanh
sigmoid와 같이 입력이 너무 크게 된다면 미분값이 사라진다.
LeakyReLU
ReLU의 죽는 영역을 커버할 수 있다.
추후 The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits 논문을 리뷰하며 여기 쓰인 Activation Function에 대해 추가하겠다.

안녕하세요, 콰트로 로켓단 로이 입니다.
간단하게 작성하려 했는데 흘려들은 것들을
한번 확인해 보는 과정에서 생각과 증명이 달라 양이 늘었습니다.
'知 > job지식' 카테고리의 다른 글
| Resnet 직관 (0) | 2024.05.05 |
|---|---|
| CNN(Convolution Neural Network) (0) | 2024.05.02 |
| MLP(Multi-Layer Perceptron)의 직관 (1) | 2024.04.24 |
| Perceptron 이란 (0) | 2024.04.22 |
| [IT] IO Error: Got minus one from a read call. (0) | 2024.04.16 |